eQube®-BI: A modern Analytics / Business Intelligence (A / BI) platform
eQube®-BI democratizes BI. It puts the power of analytics in the hands of end users.
It unshackles end users to analyze live enterprise-wide data on-demand while honoring the security rules of the underlying applications.
For too long, end users have been relying on power-users or internal IT developers to develop business critical reports, KPIs, or dashboards.
In a governed environment, these analytics artifacts are well defined and approved by the business before they are put in production.
They are typically developed by power-users or IT developers and are published at predefined frequencies or schedules
(such as daily, weekly, monthly, etc.).
This governed analytics approach is most appropriate to ensure consistency of analysis across any organization.
However, it can take weeks or more to productionize these artifacts.
With the proliferation of streaming / sensory data, needs for data scientists are also exploding.
More...
Data scientists need to harness and analyze Big data to gain insights that are business critical.
Many times, they need to aggregate Big data with core business applications’ data.
With the pace of change in any business, end users need to have on-demand access to data spread across the enterprise.
In addition, some of the end users have become ‘Citizen Data Scientists’ and have a need to rapidly build the analytics views to aid business leaders
for timely decision-making. To effectively address the needs of power-users, end users, data scientists, and citizen data scientists,
there is a clear need for a bi-modal modern A / BI platform.
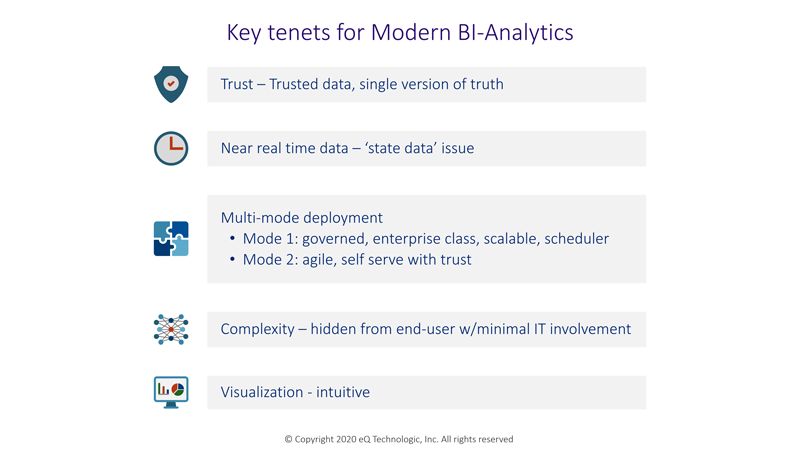
Key tenets for Modern A / BI platform are summarized in diagram shown.
Mode 1 is for the governed BI deployment for all users where the BI artifacts are developed and managed by power-user or IT developers.
While Mode 2 is for rapid and agile A / BI approach for citizen data scientists, end users, and data scientists. In both modes of deployment,
security and access control are paramount for any business. Underlying applications’ security rules are expected to be enforced in A / BI artifacts.
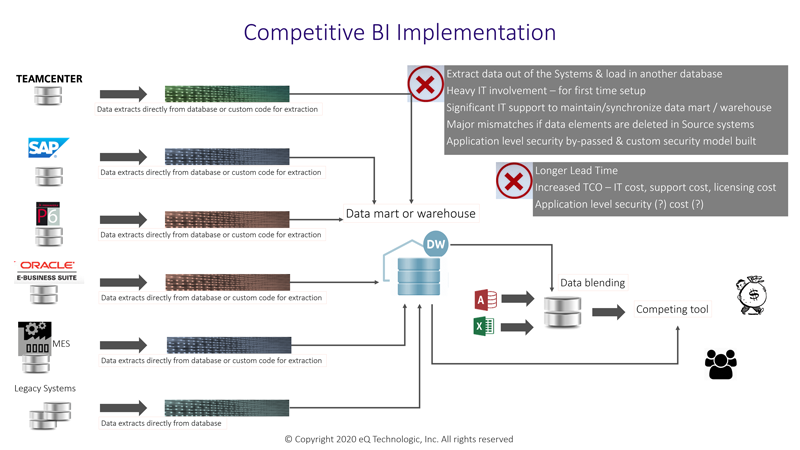
Many A / BI products approach the problem of aggregating data from across the enterprise by first developing an intermediate data store
(a Data Mart or a Data Warehouse) that stores a copy of the data from source systems. With this approach, the security and access control
rules of the underlying source systems are by-passed.
Additionally, data ETL routines must be developed, maintained, and deployed to make this
approach work. When the business conditions or requirements for analytics artifacts change or when the source systems’ versions change,
the entire infrastructure of ETL and intermediate data store must be upgraded. At times, this approach can result in data discrepancies between
source system data and intermediate store data.
Resolution of these data discrepancies can take a lot of effort and may impact the
perception of end users that they are not dealing with trust-worthy data.
ETL routines are typically run overnight and therefore,
the analytics is not real-time or near real-time. For certain business decisions, this ‘stale-data’ can be a major problem.
The shown diagram depicts the traditional approach and summarizes its challenges. This entire approach is laborious, expensive, and slow!
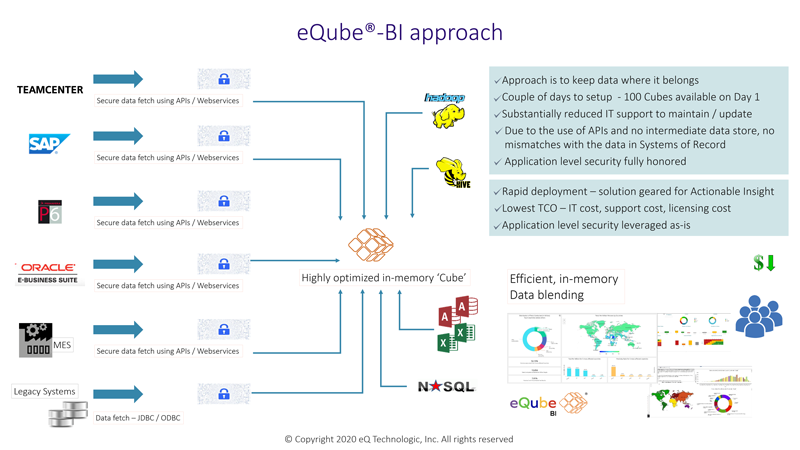
eQ’s approach is to keep data where it belongs – in the source systems. eQube®-BI can be deployed in a bi- modal manner.
It interactively mashes-up data from multiple systems with stunning visualizations to reveal the ‘story’ behind the data for Actionable Insight.
It honors and leverages the underlying applications’ security and access control rules. Therefore, end users see only the information they are
authorized to see.
Analytics artifacts can be consumed by end users in an eQube®-BI defined portal or as part of a SharePoint portal or as part of
a web-based 'For-Purpose' App or on any mobile device. It has in-built powerful scheduler that can publish the analytics artifacts for end users
in both Mode 1 and Mode 2 deployment approaches. Diagram shown depicts the eQube®-BI approach for A / BI.
eQube®-BI has in-built event management system (EMS) that generates A / BI artifacts upon certain events in underlying system (s),
such as upon executing certain step (s) in a workflow or upon state change of an object or a database record. In addition, end users can generate A / BI
artifacts in real-time on-demand.
Sentence-based analytics is fully incorporated in eQube®-BI. End users can type in their questions in plain English
in a search bar and generate A / BI artifacts due to the interaction between eQube®-BI’s powerful natural language processing (NLP) engine and its data
virtualization layer with semantic capabilities.
In addition, eQube®-BI efficiently deals with streaming /sensory data as well as Big data stores and Data Lakes to provide aggregated view across these data sources and core business systems (such as: PLM, ERP, MRO, Supply Chain, Asset management, Logistics, ALM, etc.) for critical insight. The underlying architecture is enterprise-class scalable architecture with highly optimized in-memory cubes that scales out to support thousands of end users.
eQube® believes in keeping data where it belongs – in the source systems.
However, if a customer has already invested in a Data Warehouse or Data Mart (s) or Data Lake, eQube®-BI can easily leverage it as a source for
A / BI capabilities. In addition, it can mash-up data from the Data Warehouse or Data Mart (s) or Data Lake along-with the data from other enterprise
systems (legacy, COTS, files, etc.)
Less...
Data Lake and Data Warehouse
Solutions ranging from modern BI analytics platforms, Data Warehouses, and Data Lakes are available to address various use cases.
eQube®-BI is a modern A / BI platform that addresses multiple analytics use cases for many personas (such as: a regular end user, a power-user with software background, a citizen data scientist, a data scientist, a manager or an executive, etc.).
More...
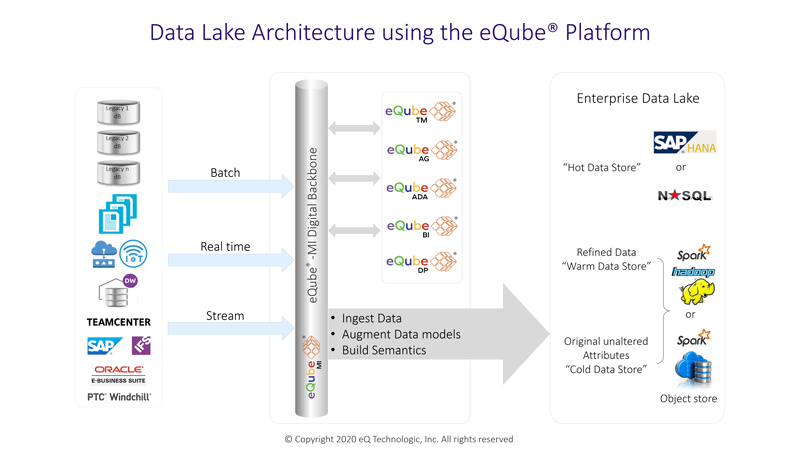
In addition, using eQube®-MI as the core platform, efficient and comprehensive solutions can be built for Data Lake and Data Warehouse initiatives.
a. Data Lake:
As shown in the diagram, data from multiple sources (files, sensors – products and machines, sentiment –
social media, databases, and COTS applications) can be ingested in a Data Lake using the eQube®-DaaS Platform. eQube®-BI
and eQube®-DP solutions are used for data discovery and preparation during the ingestion process orchestrated by
eQube®-MI while eQube®-TM maintains the knowledge base of the data augmenting the semantics information related to
the data. eQube® based approach provides a framework for efficient ingestion of raw data in a 'Cold store' and
enables orchestration for populating 'Warm store' and 'Hot store' for rapid analysis. eQube® Connectors for file
systems, COTS applications, databases, NoSQL systems, and Big data stores can be leveraged to develop and maintain
the Data Lake solution on-premise or in the Cloud.
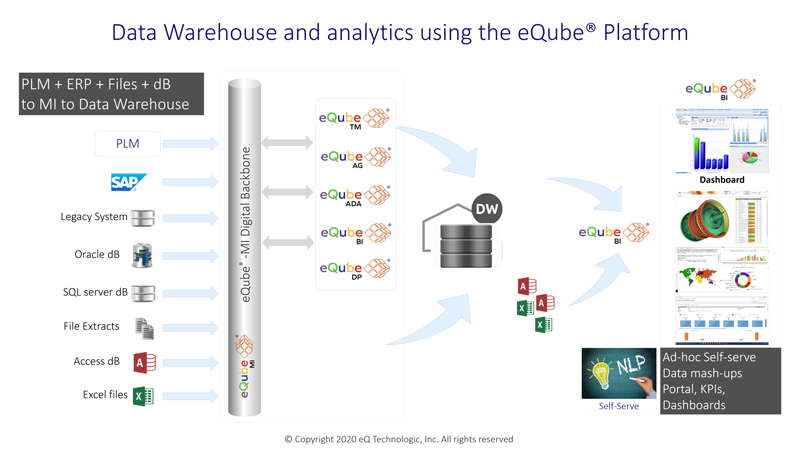
b. Data Warehouse: As shown in the diagram, data from multiple sources (text files, databases, and COTS applications) can be transformed and populated into a dimensional model in a Data Warehouse using the eQube®-DaaS Platform. eQube®-BI and eQube®-DP solutions are used for data discovery and preparation during the ETL process orchestrated by eQube®-MI while eQube®-TM maintains the knowledge base of the data augmenting the semantics information related to the data. eQube® connectors for file systems, COTS applications, and databases can be leveraged to develop and maintain a Data Warehouse solution on-premise or in the Cloud. Due to eQube's innovative architecture, using eQube® for the development and maintenance of a Data Warehouse is far more efficient than traditional approaches and tools.
- Decision-making and business performance reporting based on past performance:
- Financial reporting and analysis
- Sales and customer satisfaction analysis
- Business performance analysis
- Descriptive analytics: predominantly focused on past performance data.
If 'stale-data' is unacceptable and security / access control are critical, eQ recommends using its modern
A / BI platform, eQube®-BI. eQube®-BI aggregates data by directly connecting to SORs for providing real-time
or near-real time analytics honoring the underlying applications' security / access control rules. In this
approach, data is kept where it belongs and the need for a Data Warehouse is eliminated. However, if a
Data Warehouse already exists and data from it also needs to be aggregated with data from certain SORs,
then eQube®-BI can mash up data from both the SORs and the Data Warehouse on-demand. Thus eQube®-BI can
leverage the investments made in a Data Warehouse or Data Mart(s).
Speed, agility, and total life cycle cost of eQube®-BI based solution is far superior to a traditional Data Warehouse based analytics solution. The number of business use cases addressed by eQube®-BI based solutions tend to be extensive and therefore, it can be deployed as an enterprise-wide solution for A / BI.
Less...
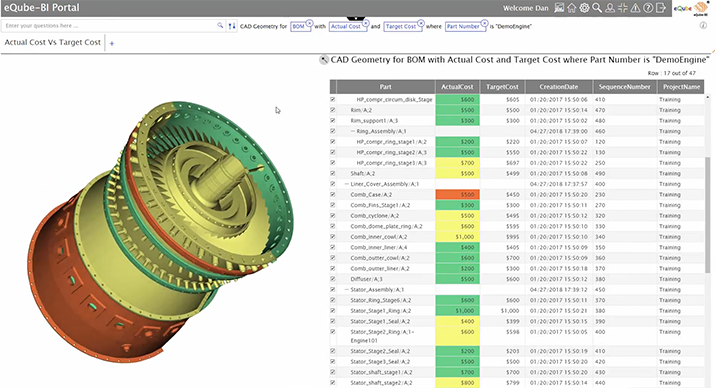
3D CAD dashboard
(Teamcenter BOM & SAP)
.png)
eQube® App on SharePoint
(eHub DDR)
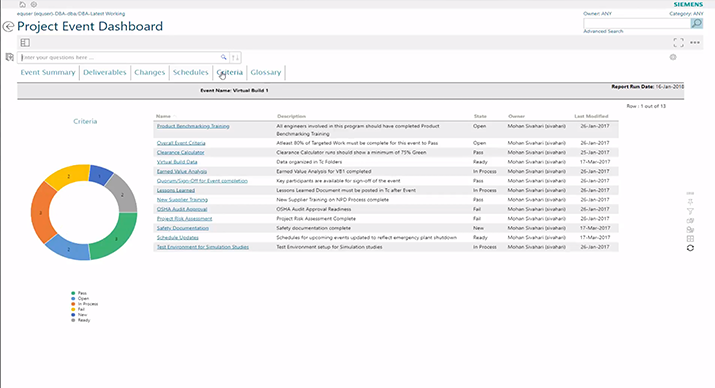
Active Workspace - 100 cubes
eQube® as well as the graphic representation of the logo of eQube with a drawing of a cube ![]() are Registered Trademarks of eQ Technologic, Inc.,
registered in the United States Patent and Trademark Office. All other logos, trademarks or service
marks used herein are the property of their respective owners. Nothing contained herein is intended to
claim ownership of, title to, interest in or sponsorship of the owners of product(s) identified by
logos, trademarks or service marks, whether or not registered, which are not specifically stated to be owned by eQ Technologic, Inc.
are Registered Trademarks of eQ Technologic, Inc.,
registered in the United States Patent and Trademark Office. All other logos, trademarks or service
marks used herein are the property of their respective owners. Nothing contained herein is intended to
claim ownership of, title to, interest in or sponsorship of the owners of product(s) identified by
logos, trademarks or service marks, whether or not registered, which are not specifically stated to be owned by eQ Technologic, Inc.